What is LoRA
LoRA is a Parameter Efficient Fine-tuning method, in this blog we have convered the logic behind it.
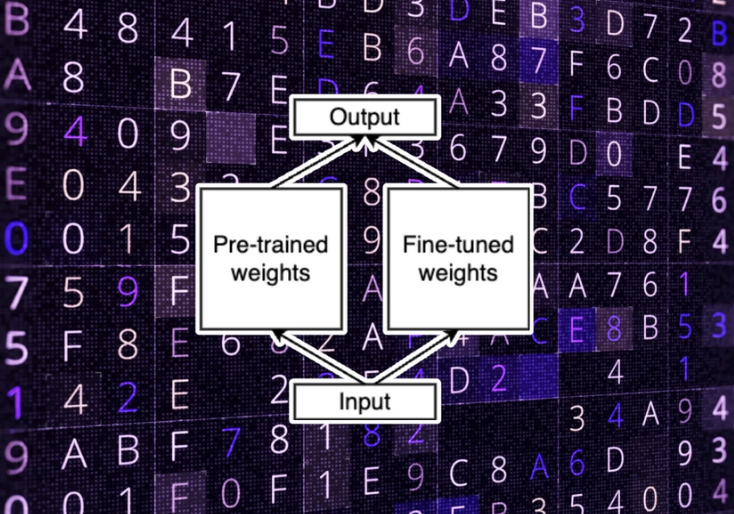
Optimizing Large Pre-Trained Models with LoRA
Fine-tuning large pre-trained models poses significant computational challenges, often requiring adjustments to millions of parameters. LoRA, an innovative approach, addresses this challenge by decomposing the update matrix during fine-tuning, offering a streamlined solution for adapting models to specific tasks.
Understanding Traditional Fine-Tuning
In traditional fine-tuning, modifications are made directly to the pre-trained neural network's weights (W) to accommodate new tasks. These adjustments, collectively represented by ΔW, are applied to the original weight matrix (W) to derive updated weights (W + ΔW).
Decomposition of ΔW
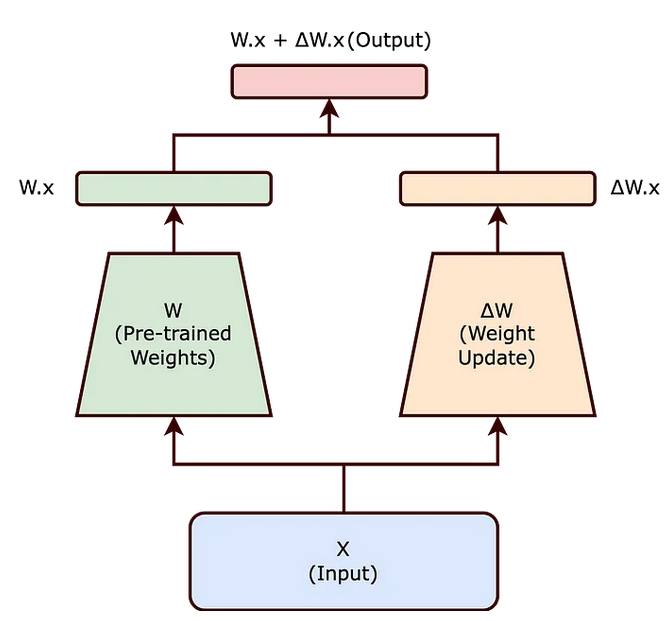
LoRA introduces a paradigm shift by decomposing ΔW into smaller matrices (A) and (B), guided by the intrinsic rank hypothesis. This hypothesis suggests that significant changes in the neural network can be captured through a lower-dimensional representation, thereby reducing computational overhead.
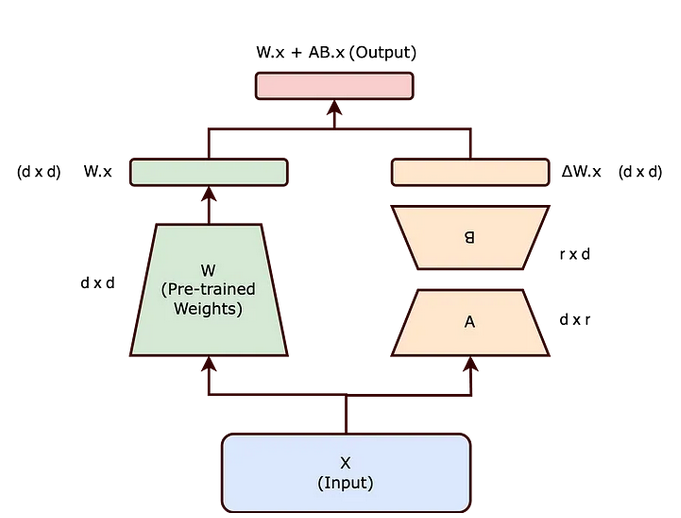
The Intrinsic Rank Hypothesis
The intrinsic rank hypothesis posits that not all elements of ΔW are equally critical. Instead, a smaller subset of changes can effectively encapsulate the necessary adjustments, leading to a more efficient representation.
Benefits of Low-Rank Adaptation (LoRA)
LoRA offers several benefits, primarily driven by the reduction in trainable parameters achieved through lower-rank matrices (A) and (B):
- Reduced Memory Footprint: LoRA decreases memory requirements by minimizing the number of parameters to update, facilitating the management of large-scale models.
- Faster Training and Adaptation: Simplifying computational demands accelerates the training and fine-tuning of large models for new tasks.
- Feasibility for Smaller Hardware: Lower parameter counts enable fine-tuning on less powerful hardware, expanding accessibility.
- Scaling to Larger Models: LoRA supports model expansion without proportionate increases in computational resources, enhancing scalability.
Rank in LoRA
The concept of rank is pivotal in LoRA, influencing the efficiency and effectiveness of the adaptation process. Remarkably, experiments demonstrate that the rank of matrices (A) and (B) can be surprisingly low, sometimes as low as one.
Applicability Across Domains
While primarily showcased in Natural Language Processing (NLP), LoRA's low-rank adaptation approach holds broad applicability across various neural network types and domains.
Conclusion
LoRA's strategy of decomposing ΔW into lower-rank matrices balances the need for model adaptation with computational efficiency. By leveraging the intrinsic rank concept, LoRA preserves the model's learning capability with significantly fewer parameters, offering a promising solution for fine-tuning large pre-trained models across diverse tasks.